Learning an interpretable coordinate system for a dataset
Author
Akshay Balsubramani
What is localization?
There are many ways to use graphs for fast and expressive nonlinear dimension reduction. Typically, the data are thought of as being sampled noisily from an unobserved lower-dimensional manifold. Our topic here is learning a “coordinate system” – a basis – on the manifold.
The most common approach is to use the eigenvectors of the graph Laplacian, also known as the graph Fourier basis. This is the basis used by spectral clustering, diffusion maps, and other common algorithms. In a broad sense, the graph Fourier basis recovers the structure in the graph at all scales, from low to high frequencies. However, this basis does not reflect interpretable fine-scale information. The basis vectors are all dense.
It turns out (Melzi et al. 2018) that this problem can be solved efficiently by surgically modifying the learning problem to give a basis that is constructed to be interpretable: sparse, localized, and non-redundant. Dimension reduction can thereby respect predefined subsets of the data in a finely tuned way. The learned basis can be constructed to be much more efficient for analysis.
Best of all, the method of modifying the learning problem for localization is very general. It can be applied to any base graph kernel.
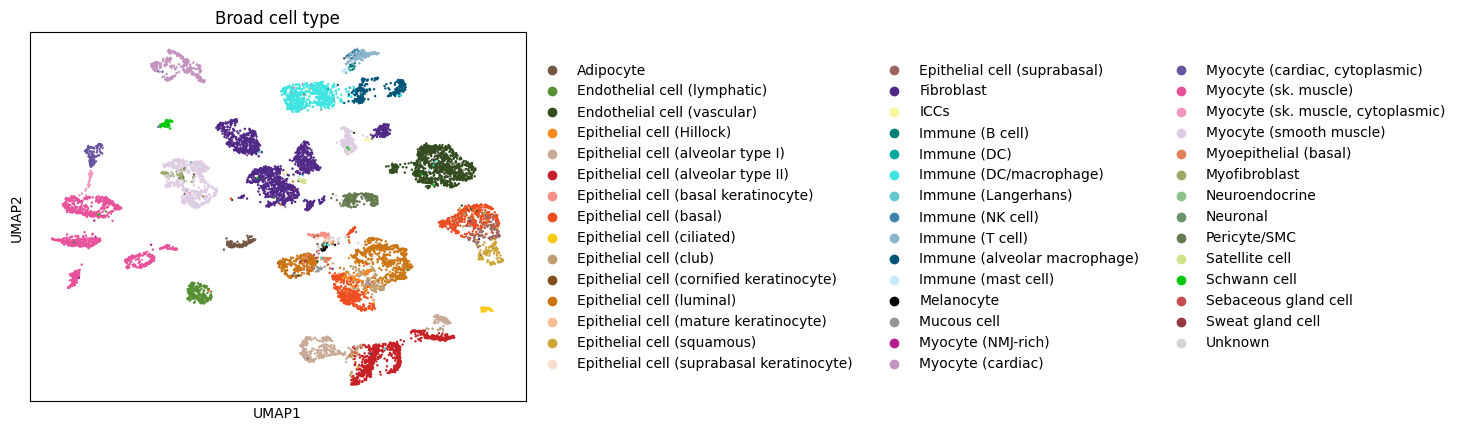
I’ll illustrate the idea with a worked example: the wonderful single-cell dataset of (Eraslan et al. 2022).
CODE
import anndata, scanpy as sc, numpy as np, pandas as pd, matplotlib.pyplot as plt, seaborn as sns, os, sys, scipy.sparse as spsc.settings.verbosity =0file_path ='../../files/omics/single_cell/GTEx_8_tissues_snRNAseq_atlas_10k.h5'adta = sc.read(file_path)sc.pp.neighbors(adta)sc.tl.umap(adta)
CODE
sc.pl.umap(adta, color=['Broad cell type'])
CODE
adj_mat = adta.obsp['connectivities']
CODE
import scipydef compute_diffusion_kernel( adj_mat, alpha=0.0, normalize=True, sym=True, self_loops=False):"""Compute the diffusion kernel of a graph [1]_ , given its adjacency matrix. Parameters ---------- adj_mat : sparse matrix Adjacency matrix of the graph. alpha : float , The exponent of the diffusion kernel. * 1 = Laplace-Beltrami (density)-normalized. * 0.5 = normalized graph Laplacian (Fokker-Planck dynamics) [2]_. * 0 = classical graph Laplacian [default]. normalize : bool Whether to normalize the transition matrix. sym : bool Whether the transition matrix normalization should be symmetric. (Relies on normalize==True). If True, the kernel is symmetric $D^{-1/2} A D^{1/2}$. If False, it is asymmetric $D^{-1} A$. self_loops : bool Whether to add self-loops to the graph [3]_. Returns ------- W : sparse matrix The diffusion's transition kernel calculated according to these parameters. References ---------- .. [1] Ronald R. Coifman, Stéphane Lafon, Diffusion maps, Applied and computational harmonic analysis 21.1 (2006): 5-30. .. [2] Boaz Nadler, Stephane Lafon, Ioannis Kevrekidis, Ronald Coifman, Diffusion maps, spectral clustering and reaction coordinates of dynamical systems, Applied and Computational Harmonic Analysis 21.1 (2006): 113-127. .. [3] Felix Wu, Amauri Souza, Tianyi Zhang, Christopher Fifty, Tao Yu, Kilian Weinberger, Simplifying graph convolutional networks, International conference on machine learning, pp. 6861-6871. PMLR, 2019. """ similarity_mat =0.5*(adj_mat + adj_mat.T) W = similarity_matif alpha !=0: dens = np.asarray(similarity_mat.sum(axis=0)) # dens[i] is an estimate for the sampling density at point i. K = scipy.sparse.spdiags(np.power(dens, -alpha), 0, similarity_mat.shape[0], similarity_mat.shape[0]) W = scipy.sparse.csr_matrix(K.dot(similarity_mat).dot(K))if self_loops: W = W + scipy.sparse.identity(W.shape[0])ifnot normalize:return Welse: z = np.sqrt(np.asarray(W.sum(axis=0)).astype(np.float64)) # sqrt(density) recipsqrt = np.reciprocal(z) recipsqrt[np.isinf(recipsqrt)] =0 Zmat = scipy.sparse.spdiags(recipsqrt, 0, W.shape[0], W.shape[0])return Zmat.dot(W).dot(Zmat) if sym else Zmat.power(2).dot(W)def compute_eigen(adj_mat, n_comps=2, sym=True):"""Wrapper to compute eigendecomposition of a sparse matrix, e.g. for dimension reduction. Parameters ---------- adj_mat : sparse matrix Adjacency matrix of the graph. n_comps : int, optional Number of eigenvectors to return. Default: 2. sym : bool, optional Whether to symmetrize the transition matrix. Default: True. Returns ------- eigvals : ndarray Vector with `n_comps` leading eigenvalues of the matrix. evecs : ndarray Matrix (n x `n_comps`), with the corresponding `n_comps` leading eigenvectors of the matrix. Notes ----- `scipy.sparse.linalg.eigsh` is used here; we use `np.linalg.eigh` if we want to support non-sparse matrices. """if sym: eigvals, evecs = scipy.sparse.linalg.eigsh(adj_mat.astype(np.float64), k=n_comps)else:# eigvals, evecs = scipy.sparse.linalg.eigs(adj_mat.astype(np.float64), k=n_comps) # DON'T USE without further thresholding: complex-number underflow issues evecs, eigvals, _ = scipy.sparse.linalg.svds(adj_mat.astype(np.float64), k=n_comps)# eigvals, evecs = eigvals.astype(np.float32), evecs.astype(np.float32) sorted_ndces = np.argsort(np.abs(eigvals))[::-1]return eigvals[sorted_ndces], evecs[:, sorted_ndces]
It is related to the smoothness (“Dirichlet energy”) of signals on the graph. To explain for any set of signals \(h_1, \dots, h_d \in \mathbb{R}^{n}\) over the graph nodes, let’s arrange them into columns of a matrix \(H\). Then \(H\) has rows \(\eta_1, \dots, \eta_n\), denoting the signals across each node. To measure the smoothness of the signals over the graph, we can use the Dirichlet energy of the signals, which is the sum of squared distances between adjacent nodes in the graph.
For constructing a basis of these signals, we’d need \(h_1, \dots, h_D\) to be orthonormal, i.e. \(H^\top H = I\). This leads to the familiar eigenproblem for the graph Laplacian:
Again, this penalizes differences in the signal over adjacent edges, and therefore encourages signals to be smooth in the learned basis. So the basis columns of \(H\) are constructed to maximally capture the components of the signal that are smoothest.
As an eigenproblem on a sparse matrix, this runs reasonably fast. In practice, we use a normalized version of the Laplacian with a similar interpretation.
The main idea of (Melzi et al. 2018) is to modify the learning problem to encourage the basis to be localized on a subset of the nodes. This is done by adding a penalty term to the learning problem, which penalizes energy lost by the basis on the complement of the subset. The basis is thereby encouraged to be smooth on the subset, and not smooth on the complement.
The penalty term is a function of a signal \(s \in [ 0,1 ]^n\); this is like an indicator function over the subset, but allows for partial membership. We penalize energy lost by the new basis outside the subset (\(1-s\)) through a penalty function \(\mathcal{R}_{S}\).
For each basis vector \(h_t\), the energy outside the subset is \(\|\| h_t
\circ (1 - s) \|\|^2\). So over the entire basis,
The final penalty for a subset is implemented below.
CODE
def subset_localizer(vec_cells_focus):""" Return a regularization term to localize over subsets of a graph with n vertices. Parameters ---------- vec_cells_focus : Boolean length-n vector indicating which cells to focus on Returns ------- scipy.sparse.csr_matrix : Sparse diagonal n x n matrix with regularization penalty """ n = vec_cells_focus.shape[0] reg_mat = scipy.sparse.spdiags(np.square(1- vec_cells_focus), 0, n, n)return reg_mat
If there are multiple subsets \(s_1, \dots, s_S\) to localize over, we can add a penalty term for each subset, and weight them differently with respective weights \(\lambda_1, \dots, \lambda_S\).
Orthogonality and progressive refinement
One more key tool remains. Given a set of existing basis vectors, we’d like to learn a new (possibly localized) basis that is not described by the existing basis. The existing basis is described by \(r\) orthonormal signals over cells (\(n\)-dimensional vectors \(\rho_1, \dots, \rho_r\) with \(\rho_{i}^\top \rho_{j} = \delta_{ij}\)), stacked as columns of a matrix \(R = \left( \rho_1 \vert \dots \vert \rho_r
\right) \in \mathbb{R}^{n \times r}\).
Suppose we want to ensure that the new basis \(h_{1:d}\) is not described by (in the subspace of) a given existing basis \(R\), i.e. \(\text{span}(\text{cols}(R))\). We penalize energy lost by the new basis \(H\) in \(\text{span}(\text{cols}(R))\):
def get_orthogonality_term(mat_current_basis):""" Get regularization terms to encourage learning features that are orthogonal to an existing basis. Parameters ---------- mat_current_basis : array Matrix of basis vectors (n rows, basis_size columns) Returns ------- scipy.sparse.csr_matrix : Sparse diagonal n x n matrix with regularization penalties for the basis """ sqbasis = np.square(mat_current_basis) n = mat_current_basis.shape[0] basis_size = mat_current_basis.shape[1] iflen(mat_current_basis.shape) >1else1 reg_mat = scipy.sparse.spdiags(np.zeros(n), 0, n, n)for ndx inrange(basis_size): new_mat = scipy.sparse.spdiags(sqbasis[:, ndx], 0, n, n) reg_mat += new_matreturn reg_mat
Putting it together
This enables sequential, attentive construction of a basis localized over successive subsets of the data. We can construct a basis incrementally, given the basis so far, and attending to a new subset of the data each time. I’ll illustrate this by focusing on a single labeled celltype at a time.
CODE
import sklearn.preprocessingfocus_cat_vec = np.array(adta.obs['Tissue'])focus_mat = sklearn.preprocessing.OneHotEncoder().fit_transform(focus_cat_vec.reshape(-1, 1)).toarray()#focus_mat = np.stack([np.ones(focus_mat.shape[0]), focus_mat]) # Add a row of ones for the "all data" category.dim_embedding =4mat_current_basis =None""" Learn a basis for a graph, with optional localization.Args: adta: Anndata object with adta.uns['neighbors']['connectivities'] = sparse adjacency matrix of combined cell graph. dim_embedding: Number of dimensions desired. vec_cells_focus: Weights in [0,1] for each cell, indicating amount of focus on each cell. regparam_focus: Relative weight of localization term in loss. mat_current_basis: Matrix of the current basis, with a column for each basis vector.Returns: basis vectors over the graph g_mat."""n = adj_mat.shape[0]keep_going =Truebasis_so_far = []graph_kern_mat = compute_diffusion_kernel(adj_mat, alpha=0.0, normalize=True, sym=True)# Attend to all the data first; initialize the basis.dim_init_emb =20new_basis = compute_eigen(graph_kern_mat, n_comps=dim_init_emb, sym=True)basis_so_far.append(new_basis[1])for subset_ndx inrange(focus_mat.shape[1]): new_kern_mat = graph_kern_mat# Attend to a subset of the data. vec_cells_focus = focus_mat[:, subset_ndx] regmat_focus = subset_localizer(vec_cells_focus) regparam_focus =10.0# Relative weight of localization penalty in loss. new_kern_mat += regparam_focus*regmat_focusiflen(basis_so_far) >0: # Learn to be orthogonal to existing basis. basis_mat = np.concatenate(basis_so_far, axis=1)print(basis_mat.shape) regmat_basis = get_orthogonality_term(basis_mat) regparam_basis =100.0# Relative weight of basis orthogonality penalty in loss. new_kern_mat -= regparam_basis*regmat_basis new_basis = compute_eigen(new_kern_mat, n_comps=dim_embedding, sym=True) basis_so_far.append(new_basis[1])print('Subset %d'% subset_ndx)
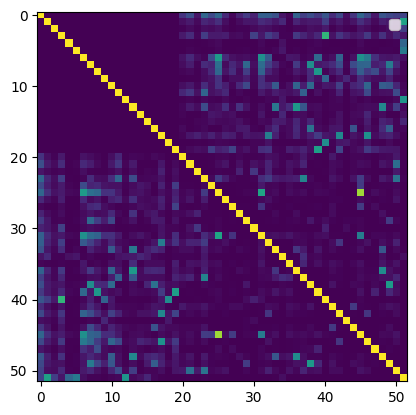
b = np.concatenate(basis_so_far, axis=1)cm = np.abs(b.T.dot(b))print(cm.max())plt.imshow(cm)plt.legend()plt.show()
1.0000000000000153
/var/folders/mn/9bz8ffcj7dj_przhmfwl3b5h0000gn/T/ipykernel_59014/2328988355.py:5: UserWarning: No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
plt.legend()
References
Belkin, Mikhail, and Partha Niyogi. 2003. “Laplacian Eigenmaps for Dimensionality Reduction and Data Representation.”Neural Computation 15 (6): 1373–96.
Coifman, Ronald R, and Stéphane Lafon. 2006. “Diffusion Maps.”Applied and Computational Harmonic Analysis 21 (1): 5–30.
Melzi, Simone, Emanuele Rodolà, Umberto Castellani, and Michael M Bronstein. 2018. “Localized Manifold Harmonics for Spectral Shape Analysis.” In Computer Graphics Forum, 37:20–34. 6. Wiley Online Library.
Ortega, Antonio, Pascal Frossard, Jelena Kovačević, José MF Moura, and Pierre Vandergheynst. 2018. “Graph Signal Processing: Overview, Challenges, and Applications.”Proceedings of the IEEE 106 (5): 808–28.
Footnotes
Here \(D = \text{diag}(A \textbf{1})\) is the degree matrix of \(G\).↩︎