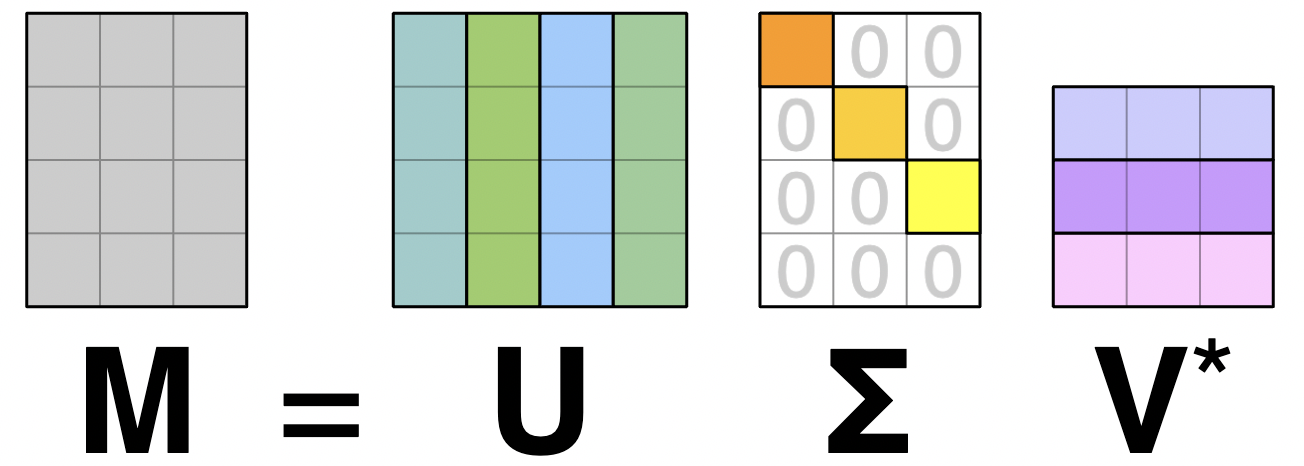
A matrix \(M\) represents a linear operator1 between two vector spaces: its domain (row space) and its range (column space). Any matrix \(M \in \mathbb{R}^{n \times d}\) of data has a singular value decomposition (SVD):
The main idea of the SVD is:
\(M\) is a dictionary mapping a basis \(V\) for the row space to a basis \(U\) for the column space.
If we write \(U\) and \(V\) as matrices with orthonormal basis-vector columns, then \(M\) can always be factored accordingly as \[ M = U \Sigma V^{\top} \]
Figure 1: How SVD works.
where:
U and V have orthonormal columns, so \(U^{\top} U = V^{\top} V = I\).
\(\Sigma\) is a non-negative diagonal matrix of singular values\(\sigma_1 \geq \sigma_2 \geq \ldots \geq \sigma_{r} > 0 = \sigma_{r+1} = \dots = \sigma_{\min(n, d)}\).
The number of nonzero singular values is the rank \(r \leq d\) of \(M\). Very often in natural science applications, we may be dealing with sparse data \(M\), where \(n\) and \(d\) are both large. The SVD is very useful as an efficient algorithmic primitive in such cases. To make this easier, I’ve found it useful to implement a few functions on top of the numpy/scipy stack, which I’m sharing here.
Applying the SVD
Truncation and randomization
The rank-\(k\) truncated SVD zeroes out the smallest singular values to leave only \(k\) of them nonzero, and is the best low-rank approximation to the original matrix. The Eckart-Young-Mirsky theorem is a classic result showing this:
The rank-\(k\) SVD of \(M\) provides the best approximation to \(M\) of rank \(k\), according to any unitarily (i.e. change-of-basis) invariant norm.
This motivates truncation of the SVD, calculating only the top few singular vectors without ever trying to calculate the rest. Among the computational tricks to compute the SVD quickly, truncation is crucial for many data matrices, whose singular values decay quickly. It is the basis for the ubiquitous use of PCA for dimensionality reduction of data.2 Typically, the signal in the data concentrates in the first few singular vectors.
To compute a \(k\)-component SVD, another essential technique is randomization(Halko, Martinsson, and Tropp 2011): reduce the number of columns in the matrix \(M\) to just over \(k\) with random projections, and compute the SVD of this much smaller matrix. In practice, this is indispensable to computing quick truncated SVDs, especially on dense data. It is implemented directly in (sklearn.utils.extmath.randomized_svd).
Outside sklearn, the routine scipy.sparse.linalg.svds avoids extraneous dependencies and works directly on sparse matrices. The wrapper I use looks something like this, giving some control over the truncation and randomization.
CODE
import numpy as np, scipy, sklearndef fast_svd(A, num_comps=10):""" Compute a fast approximate truncated randomized SVD. Parameters ---------- A : numpy array or sparse matrix The (n x d) matrix to be decomposed. num_comps : int , optional The number of singular values and vectors to compute. Default = 10. Returns ------- U : numpy matrix (n x num_comps) Matrix with the left singular vectors as columns. S : numpy array (num_comps,) The singular values. Vt : numpy matrix (num_comps x d) Matrix with the right singular vectors as rows. """# If A is a dense numpy array, just use sklearn utilsifisinstance(A, np.ndarray):return sklearn.utils.extmath.randomized_svd(A, n_components=num_comps)# If A is a sparse matrix, use the sparse randomized SVD from scipy.sparse.linalg.svdelif scipy.sparse.issparse(A):return scipy.sparse.linalg.svds(A, k=num_comps)else:raiseTypeError("A must be a numpy array or sparse matrix.")
Effective rank of a matrix
A definition of the effective rank of a matrix \(M\) that turns out to be very useful is the “intrinsic dimension” of \(M\)(Martinsson and Tropp 2020):
This has some nicely interpretable properties. It is clearly \(\geq 1\), which it only attains for a rank-1 matrix. It is also \(\leq \text{rank}(M)\), attaining this upper bound when \(M\) is an orthogonal projector.
This is often extended to compute \(\text{intdim} (M^\top M) = \frac{\sum_{i=1}^n \sigma_i^2 (M)}{\max_{i} \sigma_i^2 (M)}\), called the “stable rank” of \(M\). I’ve used both in the past, with the same fast SVD routine. So practically speaking, I compute the intrinsic dimension of the best rank-\(k\) approximation to the matrix, for \(k=50\) or so.
This is a circular, unsatisfactory argument - how do we choose what rank \(k\) to use for the SVD? To resolve this, there are even faster ways to estimate the two quantities appearing in \(\text{intdim}\)(Martinsson and Tropp 2020):
The trace \(\text{tr} (M)\) can be estimated in an unbiased way projected along any white-noise test vector, and these estimates can be averaged to give an accurate approximate trace.
The maximum singular value \(\left\| M \right\|\) can be estimated by power iteration (which converges exponentially fast).
These are both very fast and easy to implement for sparse matrices in particular, requiring just matrix-vector products (Martinsson and Tropp 2020).3 The resulting ultra-efficient way of estimating the rank of a matrix using randomized methods is below.
CODE
def intdim_matrix(M, mode='intrinsic', num_comps=50):"""Compute the intrinsic dimension of a matrix. Does a quick approximation, by computing the intrinsic dimension of the best rank-k approximation to the matrix. Parameters ---------- M : ndarray Matrix to compute intrinsic dimension of. mode : str Mode of computation. Options are 'intrinsic' (default) and 'stablerank'. Returns ------- intdim : float Intrinsic dimension of the matrix. """# U, S, V = fast_svd(M, num_comps=num_comps)# return np.sum(S**2) / np.sum(S)**2return1.0*est_trace(M)/max_eigval(M)def est_trace(M, num_trials=100):"""Estimate the trace of a matrix using the simple randomized trace estimator. Algorithm 1 of https://arxiv.org/pdf/2002.01387.pdf. Parameters ---------- M : ndarray Matrix to estimate trace of. Returns ------- trace_mean, trace_std : float , float Estimated trace of matrix, and its standard deviation over trials. """ ests = []for i inrange(num_trials):#test_vec = np.random.randint(2, size=M.shape[0]) test_vec = np.random.standard_normal(M.shape[0]) ests.append(np.dot(test_vec, M.dot(test_vec))) return np.mean(ests), np.std(ests)def max_eigval(M):""" Compute the maximum eigenvalue of a matrix using the randomized power method. Algorithm 4 of https://arxiv.org/pdf/2002.01387.pdf. Parameters ---------- M : ndarray Matrix to compute maximum eigenvalue of. Returns ------- max_eigval : float Maximum eigenvalue of matrix. """ x = np.random.standard_normal(M.shape[0]) x = x / np.linalg.norm(x) singval_old =0for i inrange(100): x_new = M.dot(x) singval = np.dot(x_new, x) x_new = x_new / np.linalg.norm(x_new)ifabs(singval - singval_old) < singval*1e-6:break x = x_new singval_old = singvalreturn singval
Polar decomposition and orthogonal matrices
Any matrix \(M \in \mathbb{R}^{n \times d}\), with \(n \geq d\), can be decomposed into a product of a matrix \(W \in \mathbb{R}^{n \times d}\) and a positive semidefinite matrix \(P \in \mathbb{R}^{d \times d}\):
\[ M = U \Sigma V^\top = \underbrace{(U V^\top)}_{W} \underbrace{(V \Sigma V^\top)}_{P} = W P \]
This is the polar decomposition of \(M\). It is fairly analogous to the magnitude-phase representation of complex numbers. The matrix \(W\) is analogous to the phase, and \(P\) is analogous to the magnitude.
It’s implemented in scipy.linalg.polar in a way that doesn’t use sparse-friendly or truncated versions of the SVD, making it unsuitable for many purposes.
Polar iteration
There is an iterative scheme to compute the polar decomposition of a matrix (Higham and Schreiber 1990), which is very fast and easy to implement. After initializing \(W_{0} := M\), the following iteration converges to the polar factor \(W\) of \(M\):
\[ W_{k+1} := W_{k} \left( I + \frac{1}{2} \left( I - W_{k}^\top W_{k} \right) \right) \]
The convergence of this iteration can be measured in terms of the residual matrix \(R_{k} := \left( I - W_{k}^\top W_{k} \right)\). \(R_{k}\) satisfies the following recursion:
The iteration converges when \(\left\| R_{k}
\right\| \leq \epsilon\) for some tolerance \(\epsilon\) . If \(\left\| R_{k} \right\| \leq \frac{1}{2}\), then
so $ | R_{k} | ^{-k} $ if $| R_{0} | $; the iteration converges exponentially.
CODE
def polar_decomp( A, mode='iterative', num_comps=10, eps_tol=1e-4):""" Compute the polar decomposition of a matrix. Parameters ---------- A : ndarray An (n x d) matrix. mode : str Mode of computation. Options are 'iterative' (default) and 'direct'. num_comps : int Number of singular values to compute. Returns ------- W : ndarray The "rotation" (phase) component of A. P : ndarray The "magnitude" component of A. """if mode =='direct': u, s, vh = fast_svd(A, num_comps=num_comps) w = u.dot(vh) p = (vh.T * s).dot(vh)elif mode =='iterative': w = A resid_norm =1.0while resid_norm > eps_tol: idmat = scipy.sparse.eye(A.shape[1]) idfac =3.0*idmat - w.T.dot(w) resid = idfac -2.0*idmat w =0.5*w.dot(idfac) resid_norm = scipy.linalg.norm(resid, ord=1) p =0.5*(w.T.dot(A) + A.T.dot(w))return w, p
For more on matrix nearness problems, see this tweet.
Data whitening
An important use of the SVD is to whiten data - that is, to transform it so that the \(d \times d\) covariance matrix \(C = \frac{1}{n} X^T X\) is the identity matrix. If \(n\) samples of data are available with \(d\) features, then the data matrix \(X\) is \(n \times d\).
There are many ways to do this, all involving the SVD applied to various matrices (Kessy, Lewin, and Strimmer 2018). I’ve implemented a few for ease of use.
ZCA whitening: This operates on either the covariance or correlation matrix, scaling by the inverse square root of this covariance (Mahalanobis norm).
PCA whitening: This operates on either the covariance or correlation matrix, projecting on its principal components.
Cholesky whitening: This operates on the covariance matrix, projecting to the Cholesky decomposition of the covariance matrix.
CODE
from scipy import statsdef whiten_data( data_mat, whiten_mode='zca', use_correlation=True, num_components=10):"""Whiten data matrix. Parameters ---------- data_mat : sparse matrix (n x d) matrix of n samples of d features. Assumes data are already centered, i.e. the average of each column is zero. whiten_mode : str in {'zca', 'pca', 'cholesky'} Method of whitening. 'zca' and 'pca' are covariance-based whitening. 'cholesky' is Cholesky decomposition-based. use_correlation : bool Whether to use correlation matrix (use_correlation==True) instead of covariance matrix (use_correlation==False). num_components : int Number of SVD components to keep. Returns ------- whitened_data : sparse matrix Matrix of whitened data, with n rows. Vt : ndarray , optional If whiten_mode is 'pca', returns the right singular vectors of the SVD of the data matrix. """if use_correlation: variances = data_mat.power(2).sum(axis=0) recipsqrt = np.reciprocal(np.sqrt(variances)) recipsqrt[np.isinf(recipsqrt)] =0 scalemat = scipy.sparse.spdiags(recipsqrt, 0, W.shape[0], W.shape[0]) data_mat = data_mat @ scalematif whiten_mode =='cholesky': cov_array = data_mat @ data_mat.T # make matrix symmetric positive definite L = np.linalg.cholesky(cov_array) cov_object = stats.Covariance.from_cholesky(L) whitened_data = cov_object.whiten(data_mat)return whitened_dataelse: U, S, Vt = fast_svd(data_mat, num_comps=num_components) scaled_basis_reduction = Vt.T.dot(scipy.sparse.spdiags(np.reciprocal(np.sqrt(S)), 0, S.shape[0], S.shape[0])) # (d x num_components) whitened_data = data_mat.dot(scaled_basis_reduction)if whiten_mode =='pca':return whitened_dataelif whiten_mode =='zca':return whitened_data, Vt
Aligning matrices
There’s a whole range of problems that encompass the idea of aligning matrices, representing datasets or coordinate systems, by finding an optimal linear transformation between them. Invariably, the SVD is used to compute this transformation for large-scale usage.
For this purpose, suppose we have two matrices \(X \in \mathbb{R}^{n \times d} , Y \in \mathbb{R}^{n \times d}\).
The best rotation matrix
The problem of finding the optimal rotation between two sets of points is known as the orthogonal Procrustes problem5, or Wahba’s problem:
\[ R^* = \arg\min_{R \in \mathbb{R}^{d \times d} : R^\top R = I} \left\| A R - B \right\|^2 \]
The objective function here is $| A R - B |^2 = | A R |^2 + | B |^2 - 2 ; (RAB) = | A |^2 + | B |^2 - 2 ; (RAB) $. This is minimized by computing the SVD of $ A^B = U V^$, and setting $R^* = U V^$. As with the polar decomposition above, this is nicely implemented in scipy, but without using a truncated SVD. I therefore adapt the latter implementation, to get something much stronger than initially.
CODE
def closest_rotation(A, B=None):"""Find the closest rotation matrix in the Frobenius norm to one matrix, or between two matrices. Parameters ---------- A : :obj:`np.ndarray` (n x d) matrix. B : :obj:`np.ndarray`, optional (n x d) matrix. If provided, the returned matrix will be the rotation matrix that best maps A to B. Otherwise, it'll be the closest rotation matrix to A. num_comps : int, optional Number of singular values to compute. Default is 10. Returns ------- :obj:`np.ndarray` : (d x d) rotation matrix. The matrix solution of the orthogonal Procrustes problem. Minimizes the Frobenius norm of ``(A @ R) - B``, subject to ``R.T @ R = I``. """ B.T.dot(A).T W, _ = polar_decomp( , mode='iterative', eps_tol=1e-4 )return W
The best relabeling matrix
Applied to already dimension-reduced data, this type of method can be very powerful. Umeyama’s theorem is a classic result in this vein that shows what’s possible (Umeyama 1988). This was applied (Mateus et al. 2008) to diffusion-maps representations of the graphs, which is something we can very easily do for approximate graph matching.
Common correlations
The problem is to find directions of common correlation between two datasets (matrices) \(X\) and \(Y\). Scikit-learn is once again a good source for these methods, implementing many of them. A couple of these can be performed solely using the SVD, making them ultra-fast.
Partial least squares
A very straightforward way of learning directions of common correlation is to try to maximize the correlations of the projected data:
This is solved by taking the SVD of $ X^top Y $ and taking the first left and right singular vectors. Similarly, taking the first \(k\) pairs of left and right singular vectors gives the first \(k\) directions of common correlation. This is implemented in sklearn.cross_decomposition.PLSSVD.
Canonical correlation analysis
A more sophisticated way of learning directions of common correlation is CCA, which tries to ensure that the data are minimally separated after projection to the common space.
\[
\begin{align}
\arg\min_{ \left\| X h_X \right\| = \left\| Y h_Y \right\| = 1} \left\| X h_X - Y h_Y \right\|^2
&= \arg\max_{ \left\| X h_X \right\| = \left\| Y h_Y \right\| = 1} (X h_X)^\top Y h_Y \\
&= \arg\max_{ h_X , h_Y \in \mathbb{R}^n} \frac{ (X h_X)^\top Y h_Y
}{ \left\| X h_X \right\| \cdot \left\| Y h_Y \right\| } \\
&= \arg\max_{ h_X , h_Y \in \mathbb{R}^n} \frac{ (X h_X)^\top Y h_Y }{ (h_X^\top X^\top X h_X)^{1/2} (h_Y^\top Y^\top Y h_Y)^{1/2}}
\end{align}
\]
This is solved by taking the SVD of the whitened covariance matrix \((X^\top X)^{-1/2} X^\top Y (Y^\top Y)^{-1/2}\).
CODE
def common_correlations( X, Y, n_components=10, method="pls", random_state=None):"""Compute common correlations between two matrices X and Y. Parameters ---------- X : ndarray or sparse matrix, shape (n, d) First matrix. Y : ndarray or sparse matrix, shape (n, d) Second matrix. n_components : int or None, optional (default=10) Number of components to keep. method : str, optional (default="pls") Method to use for computing common correlations. Options are "pls" (partial least squares) or "cca" (canonical correlation analysis). random_state : int, RandomState instance or None, optional (default=None) Returns ------- U : ndarray, shape (n, n_components) Left singular vectors of the common correlation matrix. """ C = np.dot(X.T, Y) U, s, Vt = fast_svd(C, num_comps=n_components, random_state=random_state)
Spectral coembedding and visualization of any matrix
An important application of the rank-\(k\) SVD is to model a matrix’s rows and columns in the diagonalized SVD-component space. In this space, each row and each column can be represented as a vector of length \(k\). These vectors can be embedded and used to cocluster the matrix’s rows and columns.
This uses a function compute_coclustering which groups the rows and columns, and returns the cluster indices and IDs.
We focus on one operation in particular: ordering the rows and columns of the heatmap to emphasize the internal structure. This can be done with co-clustering – assigning joint cluster labels to the rows and columns of the heatmap.
There are many methods for co-clustering, including work linking it to information theory (Dhillon, Mallela, and Modha 2003). I’ll use the most efficient, the spectral partitioning method of (Dhillon 2001). This is implemented in Scikit-learn. Here’s a wrapper around it setting it up for use.
Warning: Negative values in the original data matrix can cause significant issues; ideally, all entries are zero or higher at the start.
CODE
def scale_normalize(X):""" Normalize nonnegative ``X`` by scaling rows and columns independently. Returns the normalized matrix and the row and column scaling factors. """ row_diag = np.asarray(1.0/ np.sqrt(X.sum(axis=1))).squeeze() col_diag = np.asarray(1.0/ np.sqrt(X.sum(axis=0))).squeeze() row_diag[np.isinf(row_diag)] =0 col_diag[np.isinf(col_diag)] =0 row_diag = np.where(np.isnan(row_diag), 0, row_diag) col_diag = np.where(np.isnan(col_diag), 0, col_diag)if scipy.sparse.issparse(X): n_rows, n_cols = X.shape r = scipy.sparse.dia_matrix((row_diag, [0]), shape=(n_rows, n_rows)) c = scipy.sparse.dia_matrix((col_diag, [0]), shape=(n_cols, n_cols)) an = r * X * celse: an = row_diag[:, np.newaxis] * X * col_diagreturn an, row_diag, col_diagfrom sklearn.utils.extmath import randomized_svddef spectral_coembed( X, n_clusters=25, n_components=2, n_discard=1):""" Compute a spectral coembedding of a matrix. Parameters ---------- X: (n x d) data matrix used, n observations by d features. Returns ------- Spectral coembedding of (n + d) rows and columns of X; first the rows, then the columns. Uses (n_components - n_discard) components. """ itime = time.time() normalized_data, row_diag, col_diag = scale_normalize(X) n_sv =1+int(np.ceil(np.log2(n_clusters))) if n_components isNoneelse n_components u, _, vt = randomized_svd(normalized_data, n_sv) u = u[:, n_discard:] v = vt[n_discard:].T z = np.vstack((row_diag[:, np.newaxis] * u, col_diag[:, np.newaxis] * v))print("Coembedding computed. Time: {}".format(time.time() - itime))return zfrom sklearn.cluster import SpectralCoclusteringdef compute_coclustering( fit_data, num_clusters=1, mode='custom'):if num_clusters ==1: num_clusters =1+int(np.ceil(np.log2(min(fit_data.shape[0], fit_data.shape[1])) ))if mode =='sklearn':if scipy.sparse.issparse(fit_data): fit_data = fit_data.toarray() row_labels, col_labels = cocluster_core_sklearn(fit_data, num_clusters)return (np.argsort(row_labels), np.argsort(col_labels))elif mode =='custom': z = spectral_coembed(fit_data, n_clusters=n_clusters, n_components=2) n_rows = fit_data.shape[0] fiedler_vec = z[:, 0]return np.argsort(fiedler_vec[:n_rows]), np.argsort(fiedler_vec[n_rows:])def cocluster_core_sklearn( fit_data, num_clusters, random_state=0): model = SpectralCoclustering(n_clusters=num_clusters, random_state=random_state) model.fit(fit_data)return model.row_labels_, model.column_labels_
Lemmas 44-45 of (Woodruff 2014) tell us how to efficiently compute low-rank approximations by using Clarkson-Woodruff sketching, which takes random linear combinations of the rows of a matrix \(A\) to produce a smaller matrix \(SA\). In short, if \(S\) is a \(k \times n\) sketching matrix, then we can compute a low-rank approximation of the column space of \(A\) by computing the truncated SVD of \(SA\). A similar result holds for the row space of \(SA\) as well.
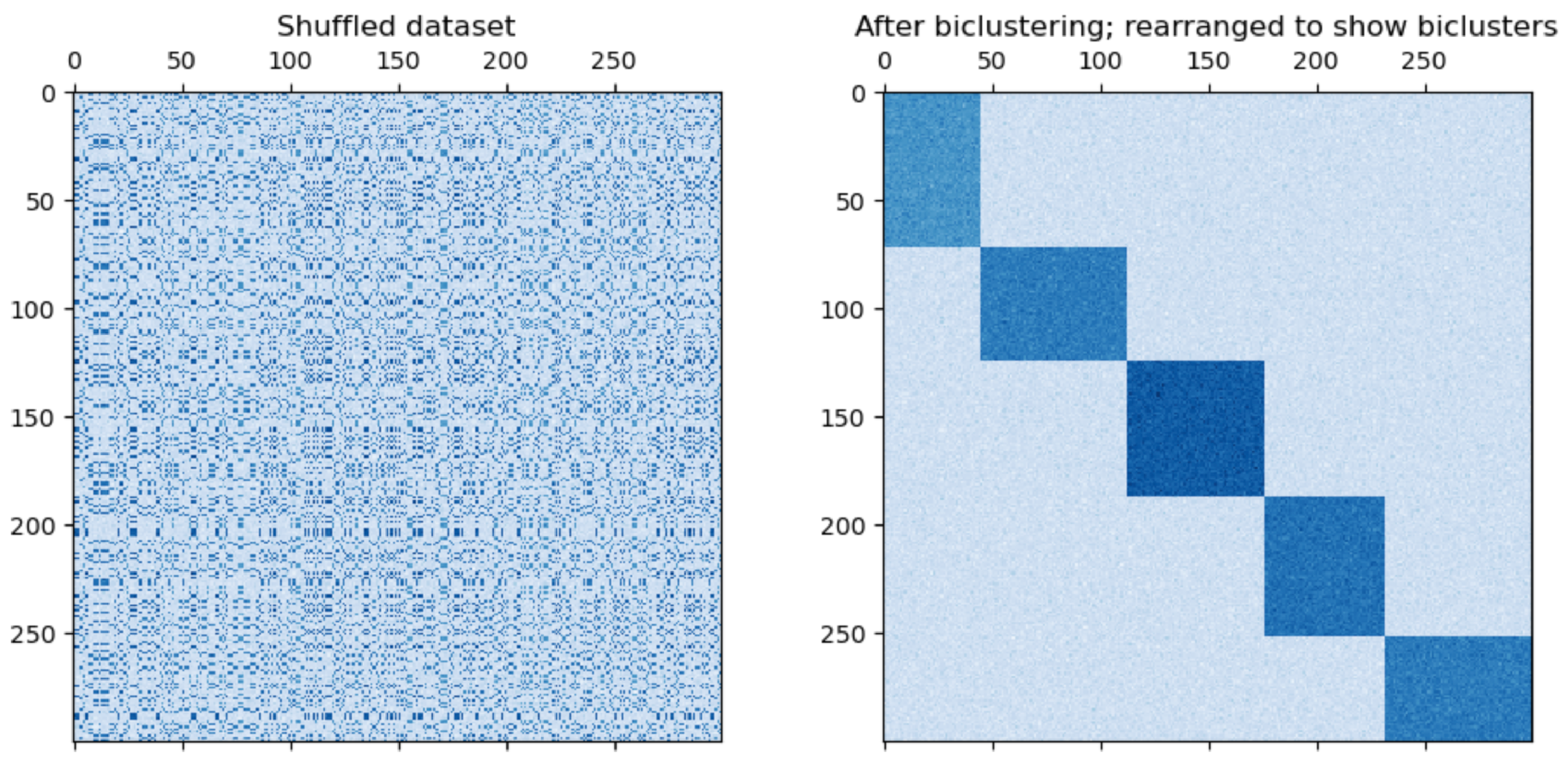
What it does: reorder the data
Once data are co-clustered, simply arranging them according to their co-cluster labels, so that rows and columns of the same label are in contiguous blocks, reveals latent structure visually in an appealing way.
The question is: how does this method find such an ordering efficiently?
Why it’s efficient: it relies on linear algebra
The algorithm is based on the following intuition:
Find a clustering that minimizes entries off the block diagonal.
This is done in a couple of steps:
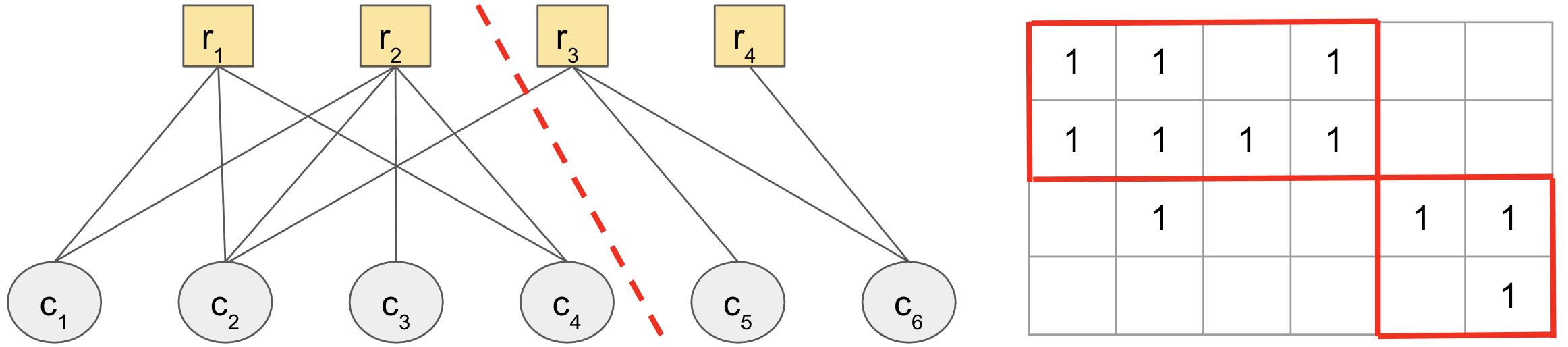
Form a bipartite graph from the data matrix, where the rows and columns correspond to vertices, and the entries to edges.
Find a way of cutting this graph into clusters that minimizes the weight of edges cut.
Step (2) is exactly the same problem faced by spectral clustering, which approximately finds these low-weight balanced graph cuts with linear algebra, by just finding one (or a few) eigenvectors. So it can be efficiently done for the scales of data we’re analyzing interactively.
Step (1), making a graph from the data, is where the insight and complexity come in. This makes a bold insight, in considering rows and columns all as first-class entities in the same bipartite graph. Looking at a toy example may help convince us that a minimum cut on this graph (indicated by the dashed red line) is what we want when the data show co-clustered structure.
Figure 3: A matrix of data, along with the undirected graph associated with it, whose vertices are rows/columns and edges are entries.
Different normalizations of the data will give slightly different results with this method! It pays to try row- and column-wise normalizations.
More dramatic steps like binarizing the data may also be appropriate for sparse data.
Tip: It does tend to work well when zeroes in the data can be neglected, and higher-magnitude entries are meaningful.
Warning: Watch out for all-zero rows/columns! It’s best to remove them.
SVD-based imputation of missing values
The SVD can also be used to cheaply impute values in matrices of biochemical data, as I write about in another post.
References
Dhillon, Inderjit S. 2001. “Co-Clustering Documents and Words Using Bipartite Spectral Graph Partitioning.” In Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 269–74.
Dhillon, Inderjit S, Subramanyam Mallela, and Dharmendra S Modha. 2003. “Information-Theoretic Co-Clustering.” In Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 89–98.
Halko, Nathan, Per-Gunnar Martinsson, and Joel A Tropp. 2011. “Finding Structure with Randomness: Probabilistic Algorithms for Constructing Approximate Matrix Decompositions.”SIAM Review 53 (2): 217–88.
Higham, Nicholas J, and Robert S Schreiber. 1990. “Fast Polar Decomposition of an Arbitrary Matrix.”SIAM Journal on Scientific and Statistical Computing 11 (4): 648–55.
Kessy, Agnan, Alex Lewin, and Korbinian Strimmer. 2018. “Optimal Whitening and Decorrelation.”The American Statistician 72 (4): 309–14.
Martinsson, Per-Gunnar, and Joel A Tropp. 2020. “Randomized Numerical Linear Algebra: Foundations and Algorithms.”Acta Numerica 29: 403–572.
Mateus, Diana, Radu Horaud, David Knossow, Fabio Cuzzolin, and Edmond Boyer. 2008. “Articulated Shape Matching Using Laplacian Eigenfunctions and Unsupervised Point Registration.” In 2008 IEEE Conference on Computer Vision and Pattern Recognition, 1–8. IEEE.
Umeyama, Shinji. 1988. “An Eigendecomposition Approach to Weighted Graph Matching Problems.”IEEE Transactions on Pattern Analysis and Machine Intelligence 10 (5): 695–703.
Woodruff, David P. 2014. “Sketching as a Tool for Numerical Linear Algebra.”Foundations and Trends in Theoretical Computer Science 10 (1–2): 1–157.
Footnotes
The matrix-vector product \(M x\) is the image of \(x\) under the linear operator \(M\). ↩︎
For data \(X\), the eigenvectors of the covariance \(X^\top X\) are just the right singular vectors of \(X\), which are PCA’s “principal components.”↩︎